本文最后更新于 191 天前,其中的信息可能已经有所发展或是发生改变。
前言
昨天闲来无事想训练一个AI声音模型,网上也有很多,例如AI雷军,AI丁真之类的,觉得蛮有趣,于是就在网上搜索了一下教程,发现up主花儿不哭开源了一个GPT-SoVITS的项目,于是我就自己部署下来了,版本是GPT-SoVITS-v2-240821。以下是使用过程。
下载
可以在up主花儿不哭处进行下载
使用
下载后进入根目录,点击 go-webui.bat
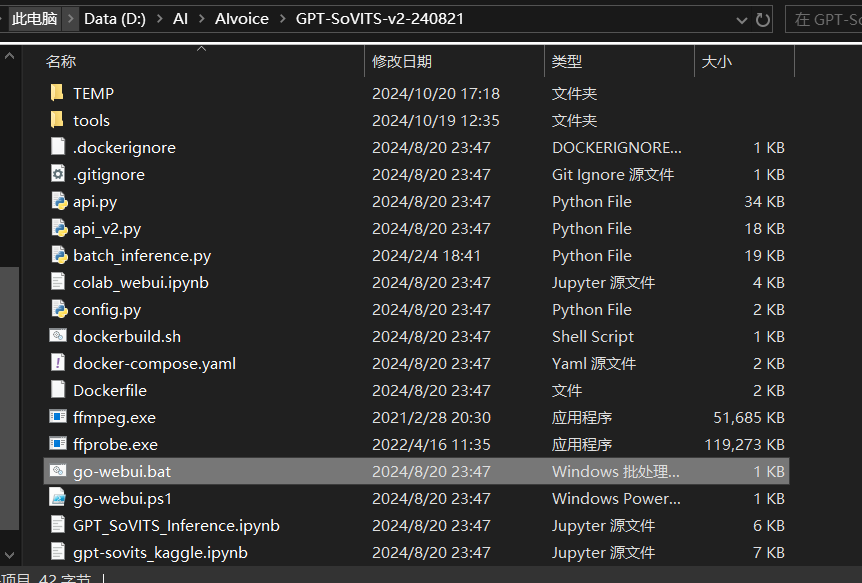
会弹出一个终端,注意不要叉掉,稍作等待会弹出一个web界面

由于许多素材带有背景音乐,因此可以采用0a-UVR5人声伴奏分离&去混响去延迟工具来分离人声和背景音乐。
点击开启UVR5-WebUI进入分离界面

然后选择模型,把素材拖进去,点击转换,会输出在根目录的output/uvr5_opt文件夹下。